2024-06-28 22:27 | 來源:天極網 | 作者:俠名 | [產業] 字號變大| 字號變小
隨著智能化技術的飛速發展,尤其是以生成式AI為代表的技術快速應用,推動了數據與智能的深化融合,給數據基礎設施帶來了新的變革和挑戰。如何簡化日益復雜的系統架構,提高...
隨著智能化技術的飛速發展,尤其是以生成式AI為代表的技術快速應用,推動了數據與智能的深化融合,給數據基礎設施帶來了新的變革和挑戰。如何簡化日益復雜的系統架構,提高數據處理效率,降低開發運維成本,促進數據開放共享和創新應用,成為企業關注的核心問題。
一站式大數據平臺,旨在通過一個平臺即可滿足各類業務需求,成為數智融合時代下數據基礎設施的發展趨勢,并從四個維度向四個“一體化”方向演進:數據架構-湖倉集一體化;數據處理-多模型一體化;數據分析-歷史與實時數據一體化;資源管理-多集群應用、資源和數據一體化。
數據架構:湖倉集一體化
過去,企業在建設數據平臺時通常使用傳統的Hadoop湖+MPP倉的混合架構,逐漸有部分企業開始使用類似Hudi/Iceberg的湖倉技術。這兩種技術架構都存在一些局限性,在線分析能力較弱,無法滿足集市業務需求。因此企業往往需要再引入額外的分析查詢引擎,用混合架構來滿足湖倉集業務需求。
混合架構中,數據需要存儲在不同平臺里來提供服務,首先就造成了數據冗余和存儲資源占用。其次,數據需要跨平臺ETL流轉,流轉開銷高,時效性較差。數據跨平臺流轉中還容易導致數據一致性問題,影響業務正確性。此外,多平臺的開發標準不一致,存在一定的技術門檻,權限管理復雜。
星環科技大數據基礎平臺TDH從2014年支持了事務表和存儲過程開始,形成了湖倉集一體雛形,在2023年TDH9.3版本中引入了湖倉集統一存儲格式Holodesk,只需一種存儲格式即可同時滿足ODS數據實時數據接入、數倉模型加工和高性能集市查詢分析等業務,不需要針對不同的業務場景使用不同的存儲引擎而構建煙囪式混合架構。在星環一體架構下,湖倉集對用戶來說,僅僅是業務邏輯上的區分,底層使用統一的技術棧,真正實現湖倉集一體化。
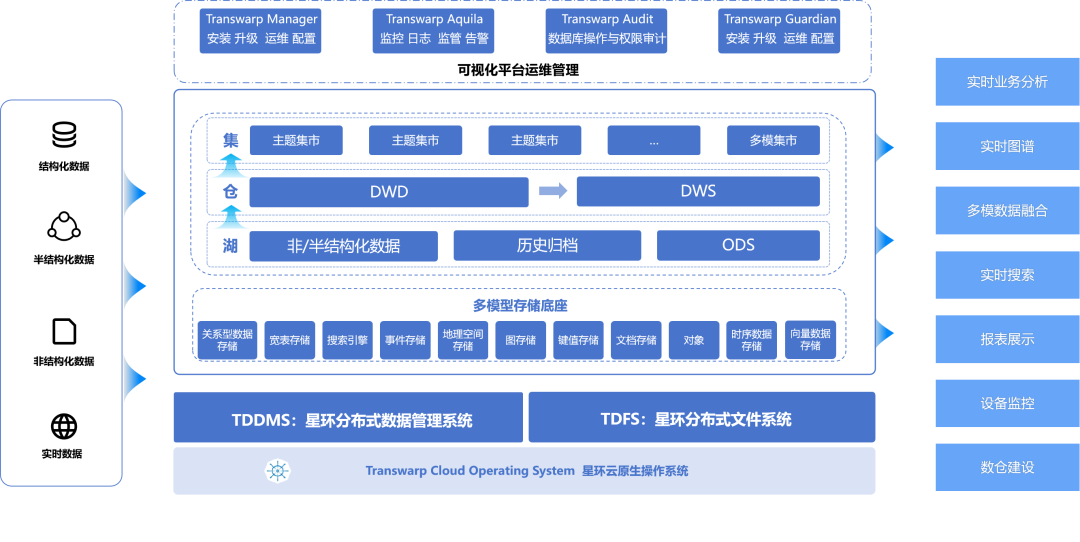
新發布的TDH9.4在資源隔離、端到端性能、統一運維管理等方面升級,幫助用戶構建真一體化、高性能、易運維的湖倉集一體化平臺。
* 資源隔離新架構,在同一份數據上跑批查詢混合負載互不影響。一套集群一份數據,基于Raft協議保障分布式一致性,在CPU、內存、IO、網絡資源方面完全隔離,結合基于容器化的動態資源調整能力,保障不同的批量業務與查詢業務性能需求。存儲方面,針對湖倉集多種混合負載業務,支持分區級多級冷熱數據存儲,*大化利用存儲資源,降低總體存儲成本。
* 端到端性能10倍提升,全面降低TCO。相比于Hudi+Clickhouse+Hbase的混合架構,TDH湖倉集同一份數據,ETL時間節約95%,存儲空間節省3/4,批量入庫性能提升3倍,實時入庫性能提升5倍,批量加工和多表關聯分析性能提升5-10倍,統計性能提升3倍,帶小量聚合的查詢業務性能提升1.5倍。
* 湖倉集統一運維管理,大幅降低運維管理成本。湖倉集統一的監控導向UI,提供更細粒度的集群運行、資源使用、組件指標等監測,提供界面化補丁管理、磁盤管理等。此外,TDH支持X86和ARM混合集群部署和統一管理,*在10000節點X86/ARM混部集群下,通過信通院云原生湖倉一體專項評測。
* 支持 Python 生態,高效支撐大模型應用。基于統一的分布式計算引擎,提供分布式Python引擎,來幫助用戶更方便地用Python進行分布式數據處理。并提供POSIX接口,掛載分布式文件系統TDFS到本體磁盤,讓用戶可以像處理本地數據一樣處理海量AI訓練數據,高效支撐數智融合時代下大模型應用和各類數據智能場景。
數據處理:多模型一體化
過去,不同的數據模型往往需要獨立的平臺來處理,而這些不同的產品在接口標準上不一致,開發者和業務分析人員需要掌握不同的語言。同樣,這些產品也使用了各自獨立的計算引擎和存儲,數據存儲在各自生態中難以互通,在業務上如果涉及到跨模型的混合業務,需要把數據從一個平臺導入到另一個平臺中,ETL流轉效率低,同時也難以保證數據的準確性、一致性和實效性。
多模數據庫旨在單個系統中集成了多個關系型和/或非關系型數據引擎(例如,文檔、圖、鍵值、時序等),滿足業務對于結構化、半結構化、非結構化數據的統一管理需求,實現數據的多模融合處理。通過使用單個系統來降低操作的復雜性,更好地支持不同場景下的多種類型數據處理。
隨著大語言模型的快速發展,對于多種模型數據的處理需求越來越高,同時由于其存在領域知識缺乏、知識時效性低、回答易幻覺、隱私數據不安全等局限性,需要通過檢索外置知識庫的方式來增強大模型能力。通過多種模型一體化處理的平臺,在增強大模型的同時,可以降低系統搭建、開發、運維等方面難度,因此多模數據庫成為大模型時代的剛需。
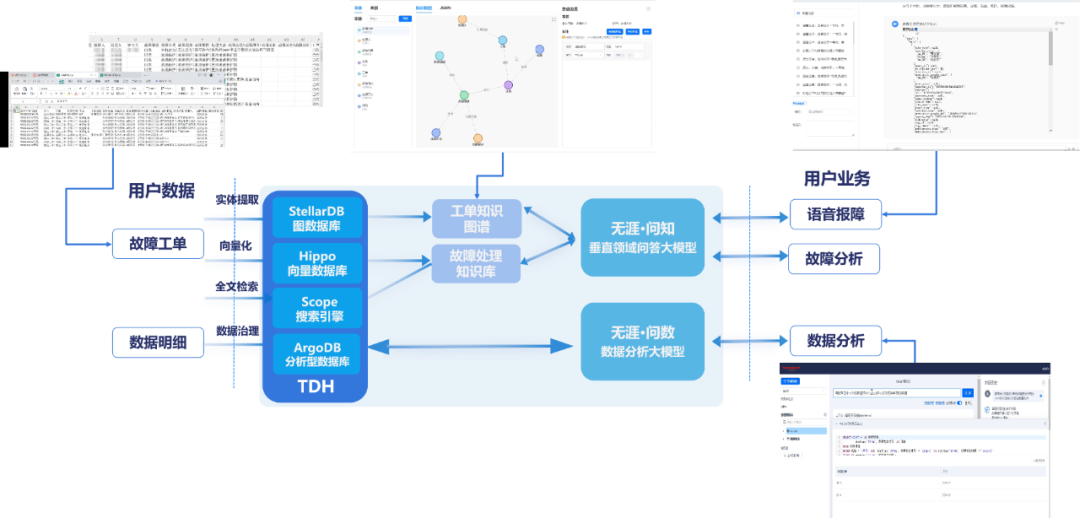
星環科技從2020年實現了多模型數據的統一處理技術,基于四層統一的架構提供統一的接口層,統一的計算引擎層,統一的分布式存儲管理層和統一的資源管理層,并支持關系型、圖、時序、時空、向量、鍵值等11種數據模型,業內*通過了信通院《多模數據庫技術要求》評測。

TDH9.4在多模型能力進行了升級,向量存儲引擎Hippo發布了2.0版本,單機存儲容量提升20倍,結合分布式架構可支持百億字的向量存儲,檢索性能提升10倍以上,并提供完整的企業級能力,包括冷熱災備、跨集群數據同步、生命周期管理等,幫助用戶更安全、便捷地支撐大模型應用。
圖存儲引擎StellarDB發布了5.1版本,引入GPU作為計算資源,部份場景下如子圖查詢性能提升10倍以上,結合深度圖算法提供圖譜召回、圖譜推理等能力,提升大模型的準確度,幫助用戶構建企業級知識庫系統。
基于TDH多模型統一技術架構,滿足大模型場景下多模態數據的統一存儲管理與服務,大幅簡化知識庫的知識存儲與服務層架構,降低開發與運維成本。通過將TDH作為大模型外置知識庫,可以檢索文本/圖片/音視頻轉化后的向量數據、圖數據、以及傳統關系型數據等,并進行聯合召回,可以極大增強大模型的準確率。
數據分析:實時與歷史數據一體化
隨著業務的快速發展以及企業內部決策的要求不斷提高,用戶對數據實時性的要求越來越迫切。實時數據處理架構Lambda和Kappa,在各自使用的場景都能解決一部分實時或近實時的用戶需求,但是隨著業務實時要求的提高,兩種架構均存在一定的不足,主要體現在:
(1)Lambda架構將實時和歷史數據分離,隨著歷史數據的積累,批量計算的性能會下降明顯;
(2)Kappa架構通過流計算的方式實現了數據融合,但流與流之間的時間窗口難以精確控制,流與流存在數據關聯不上的問題。
星環科技ArgoDB 6.1版本中推出了數據增量計算能力,提出了業務實時計算新范式。在實時處理數據架構上,解決了Lambda架構中的實時與歷史數據的不融合問題;同時避免了Kappa架構中的流與流計算窗口不可控問題。從數據的加載到數據的加工,保障了數據業務端到端的實時性能,極大地提升了業務分析的時效性。
ArgoDB6.1的增量計算技術,打破流表和物理表的使用壁壘,增量交由數據庫識別、關聯和分析:
* 大幅降低資源維護成本,窗口下沉到存儲,數據無中間狀態,流狀態時間窗口維護成本從100%降至0(即“零”維護成本);
* 實時性能 & 數據準確性提升,減少計算數據量,為結果表實時提供*新的關聯計算值;(即數據“不丟”“不重”且“計算高效”);
* 增量數據可重復使用,原始數據落表,增量的數據可供下游使用,配置鏈路簡單且數據可重復使用。
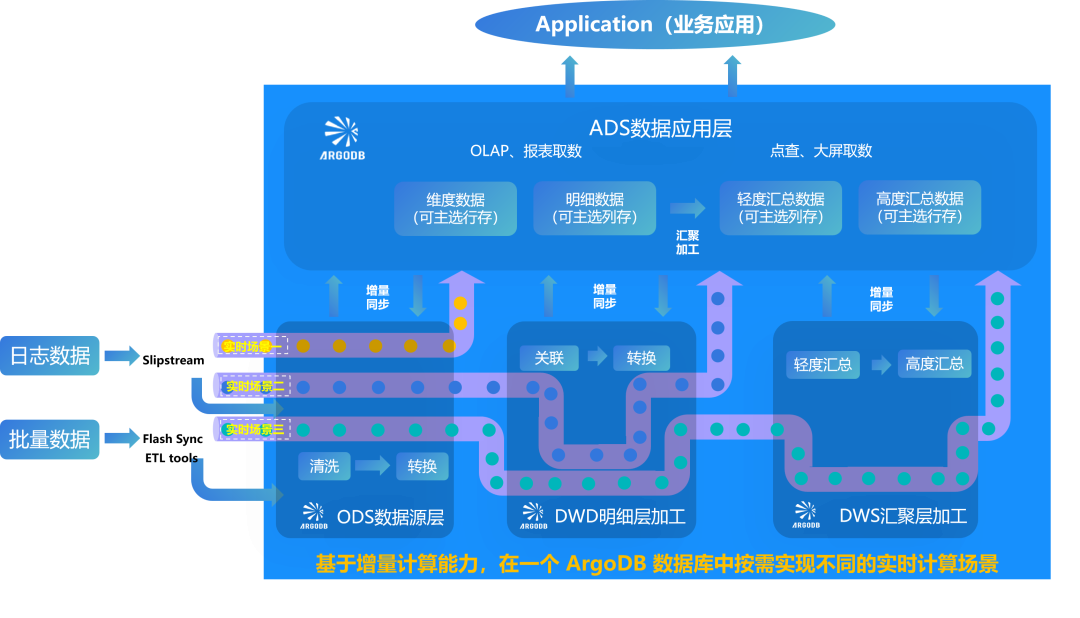
基于ArgoDB 6.1增量數據計算能力,可在一個數據庫系統中實現多種實時場景,數據僅需在庫內流轉:
場景一(即席查詢,寫入即服務):數據直接寫入ArgoDB,由ArgoDB提供OLAP 查詢和在線服務;
場景二(增量數據準實時加工):在 ArgoDB 中進行ODS數據清洗,并在DWD數據明細層預加工后直接進行匯聚層加工,對接上層應用;
場景三(增量數據實時統計,事件驅動加工):DWD明細層預加工和DWS匯聚層預加工全部由ArgoDB增量計算完成,并提供給上層應用,幫助用構建新一代的實時數據倉庫。
資源管理:多集群應用、資源和數據一體化
企業通常根據不同的業務系統構建多個不同的大數據集群,多個集群的運維管理給企業帶來了很多困擾。不同的集群各自孤立,底層資源無法統一、無法均衡的調度和*大化利用,并且各個集群上的數據難以互通,當涉及跨集群數據調用時,需要在各個集群之間ETL,效率較低,也難以保證數據的準確性、一致性和實效性。當有新業務需要上線時,需要建設新的集群,進一步加劇上述問題。
多個大數據集群統一管理,能夠將多集群統一納管,實現資源統一調度,數據統一管理,并能夠快速響應,滿足新業務上線需求。
星環科技數據云平臺TDC,在一個平臺上提供了數據PaaS、分析PaaS、應用PaaS服務,底層共享基礎設施資源,能夠實現不同業務、不同環境下的多個集群統一納管,不僅提供星環科技的大數據與人工智能產品等產品服務,也能夠托管如Spark、Flink等開源生態產品。
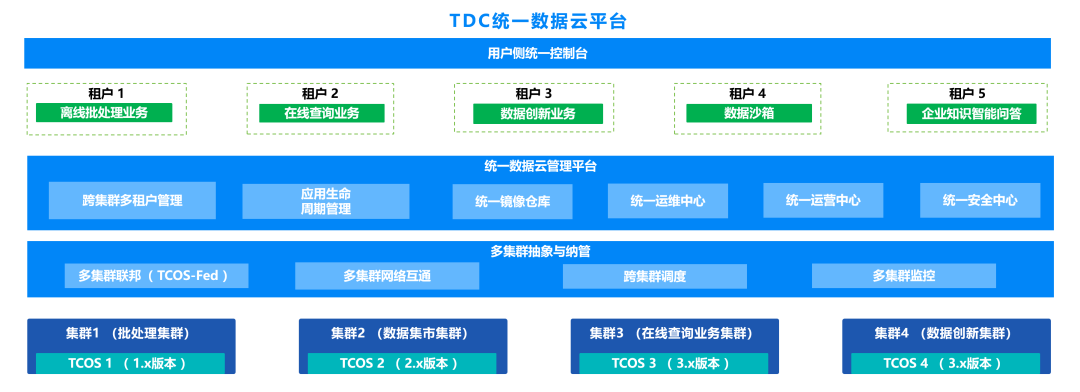
TDC 5.0在多集群及應用統一納管基礎上,對跨集群資源均衡調度、自動彈性伸縮、數據共享等能力進一步升級,幫助用戶構建一體化的大數據與智能平臺,降低企業多集群運維管理成本,*大化資源利用率,加速業務上線與創新。
跨集群資源均衡調度 實現對多個集群底層資源的統一管理,當某個集群負載較大,需要擴展存儲或者計算資源時,能夠跨集群自動調用富余集群的資源,實現多個集群之間資源的均衡調度,提升所有集群的整體資源利用率。
跨集群自動彈性伸縮 根據配置的基于時間周期、負載變化的自動彈性伸縮策略,對業務繁忙時間段和業務負載突增時,自動進行存儲和計算資源的擴縮容,滿足業務對資源的需求,保障業務性能的穩定性。
跨集群數據共享 跨多個集群實現數據的共享,集群之間不需要做ETL,可以直接共享使用對方集群的存儲,進而實現No Copy的數據共享,避免數據復制帶來的存儲壓力和數據時延,以及不一致性問題。
《電鰻快報》
熱門


 手機版
手機版
















相關新聞